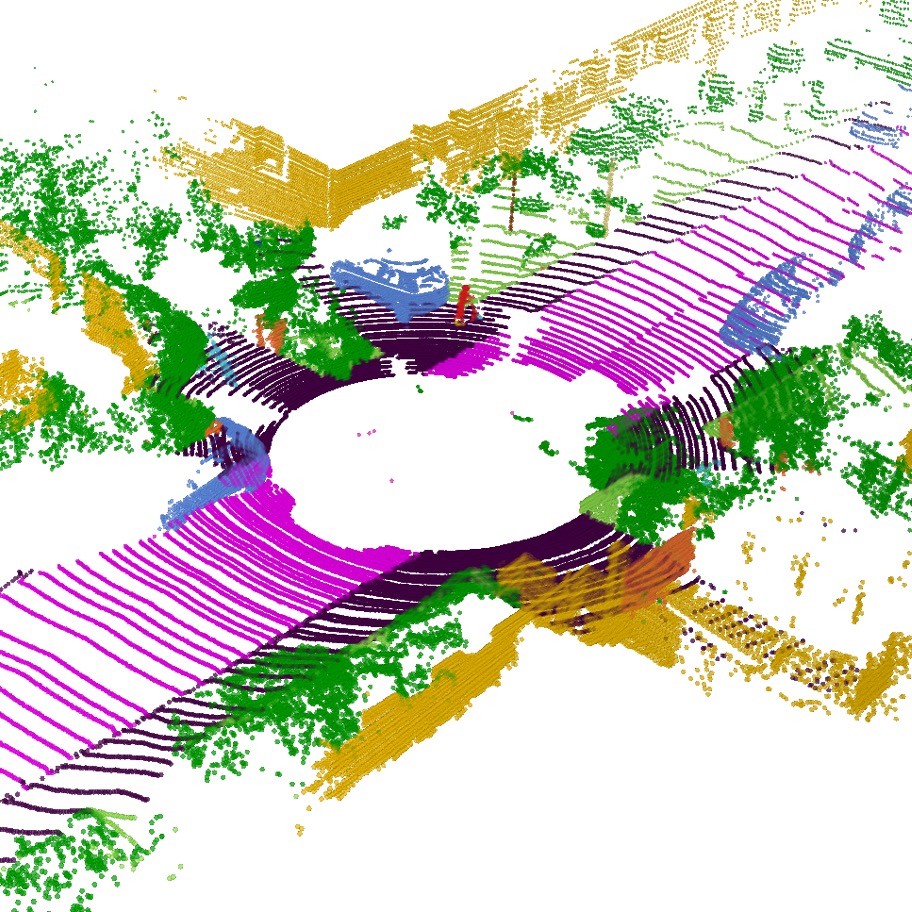
We present Dur360BEV, a novel spherical camera autonomous driving dataset equipped with a high-resolution 128-channel 3D LiDAR and a RTK-refined GNSS/INS system, along with a benchmark architecture designed to generate Bird-Eye-View (BEV) maps using only a single spherical camera. This dataset and benchmark address the challenges of BEV generation in autonomous driving, particularly by reducing hardware complexity through the use of a single 360-degree camera instead of multiple perspective cameras. Within our benchmark architecture, we propose a novel spherical-image-to-BEV (SI2BEV) module that leverages spherical imagery and a refined sampling strategy to project features from 2D to 3D. Our approach also includes an innovative application of Focal Loss, specifically adapted to address the extreme class imbalance often encountered in BEV segmentation tasks. Through extensive experiments, we demonstrate that this application of Focal Loss significantly improves segmentation performance on the Dur360BEV dataset. The results show that our benchmark not only simplifies the sensor setup but also achieves competitive performance.
@inproceedings{e2025durlar360,title={Dur360BEV: A Real-world 360-degree Single Camera Dataset and Benchmark for Bird-Eye View Mapping in Autonomous Driving},booktitle={IEEE Int. Conf. Robot. Autom},author={E, Wenke and Yuan, Chao and Li, Li and Sun, Yixin and Gaus, Yona Falinie A. and Atapour-Abarghouei, Amir and Breckon, Toby P.},publisher={IEEE},year={2025},month=jan,}
Detecting traversable pathways in unstructured outdoor environments remains a significant challenge for autonomous robots, especially in critical applications such as wide-area search and rescue, as well as in incident management scenarios such as forest fires. Current datasets and models primarily focus on either urban environments or wide vehicle-traversable off-road tracks, leaving a substantial gap in tackling the complexities of trail-based off-road scenarios. To address this issue, we introduce the Trail-based Off-road Multimodal Dataset (TOMD), a comprehensive dataset explicitly designed for narrow and unstructured trail-like environments. Our dataset features high-fidelity multimodal sensor data — including 128-channel LiDAR, stereo imagery, GNSS, IMU, and illumination measurements — collected through repeated runs across diverse environmental conditions. In addition, we propose a novel dynamic multiscale data fusion model for precise traversable pathway prediction in trail-like areas. The study investigates the impact of various fusion processes — early, cross, and mixed — on model performance under different illumination levels: low-light, normal ambient lighting, and bright conditions. The results highlight the effectiveness of our approach, performance variations across different illumination levels, and the potential applicability of the dataset in diverse environmental conditions.
@inproceedings{sun2025tomd,booktitle={Int. Joint Conf. on Neural Networks},author={Sun, Yixin and Li, Li and E, Wenke and Atapour-Abarghouei, Amir and Breckon, Toby P.},year={2025},}
arXiv
TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with Mamba
Jiaxu
Liu, Li
Li, Hubert P. H.
Shum, and Toby P.
Breckon
Diffusion models currently demonstrate impressive performance over various generative tasks. Recent work on image diffusion highlights the strong capabilities of Mamba (state space models) due to its efficient handling of long-range dependencies and sequential data modeling. Unfortunately, joint consideration of state space models with 3D point cloud generation remains limited. To harness the powerful capabilities of the Mamba model for 3D point cloud generation, we propose a novel diffusion framework containing dual latent Mamba block (DM-Block) and a time-variant frequency encoder (TF-Encoder). The DM-Block apply a space-filling curve to reorder points into sequences suitable for Mamba state-space modeling, while operating in a latent space to mitigate the computational overhead that arises from direct 3D data processing. Meanwhile, the TF-Encoder takes advantage of the ability of the diffusion model to refine fine details in later recovery stages by prioritizing key points within the U-Net architecture. This frequency-based mechanism ensures enhanced detail quality in the final stages of generation. Experimental results on the ShapeNet-v2 dataset demonstrate that our method achieves state-of-the-art performance (ShapeNet-v2: 0.14% on 1-NNA-Abs50 EMD and 57.90% on COV EMD) on certain metrics for specific categories while reducing computational parameters and inference time by up to 10x and 9x, respectively. Source code is available in Supplementary Materials and will be released upon accpetance.
@misc{liu2025tfdm,title={{{TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with Mamba}}},author={Liu, Jiaxu and Li, Li and Shum, Hubert P. H. and Breckon, Toby P.},year={2025},number={arXiv:2503.13004},primaryclass={cs},publisher={arXiv},doi={10.48550/arXiv.2503.13004},urldate={2024-05-25},}
3D point clouds play a pivotal role in outdoor scene perception, especially in the context of autonomous driving. Recent advancements in 3D LiDAR segmentation often focus intensely on the spatial positioning and distribution of points for accurate segmentation. However, these methods, while robust in variable conditions, encounter challenges due to sole reliance on coordinates and point intensity, leading to poor isometric invariance and suboptimal segmentation. To tackle this challenge, our work introduces Range-Aware Pointwise Distance Distribution (RAPiD) features and the associated RAPiD-Seg architecture. Our RAPiD features exhibit rigid transformation invariance and effectively adapt to variations in point density, with a design focus on capturing the localized geometry of neighboring structures. They utilize inherent LiDAR isotropic radiation and semantic categorization for enhanced local representation and computational efficiency, while incorporating a 4D distance metric that integrates geometric and surface material reflectivity for improved semantic segmentation. To effectively embed high-dimensional RAPiD features, we propose a double-nested autoencoder structure with a novel class-aware embedding objective to encode high-dimensional features into manageable voxel-wise embeddings. Additionally, we propose RAPiD-Seg which incorporates a channel-wise attention fusion and two effective RAPiD-Seg variants, further optimizing the embedding for enhanced performance and generalization. Our method outperforms contemporary LiDAR segmentation work in terms of mIoU on SemanticKITTI (76.1) and nuScenes (83.6) datasets.
@inproceedings{li2024rapidseg,title={{{RAPiD-Seg}}: {{Range-Aware}} {{Pointwise Distance Distribution}} {{Networks}} for {{3D LiDAR Segmentation}}},author={Li, Li and Shum, Hubert P. H. and Breckon, Toby P.},keywords={point cloud, semantic segmentation, invariance feature, pointwise distance distribution, autonomous driving},year={2024},month=jul,publisher={{Springer}},booktitle={European Conference on Computer Vision (ECCV)},note={<strong style="color:#CC0000;">Oral Presentation</strong> (2.3% = 200/8585)}}
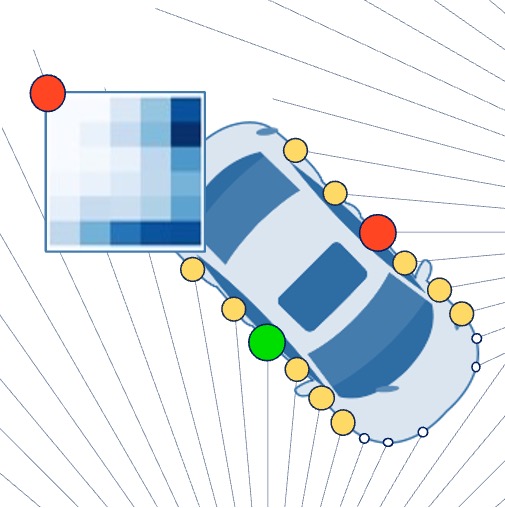
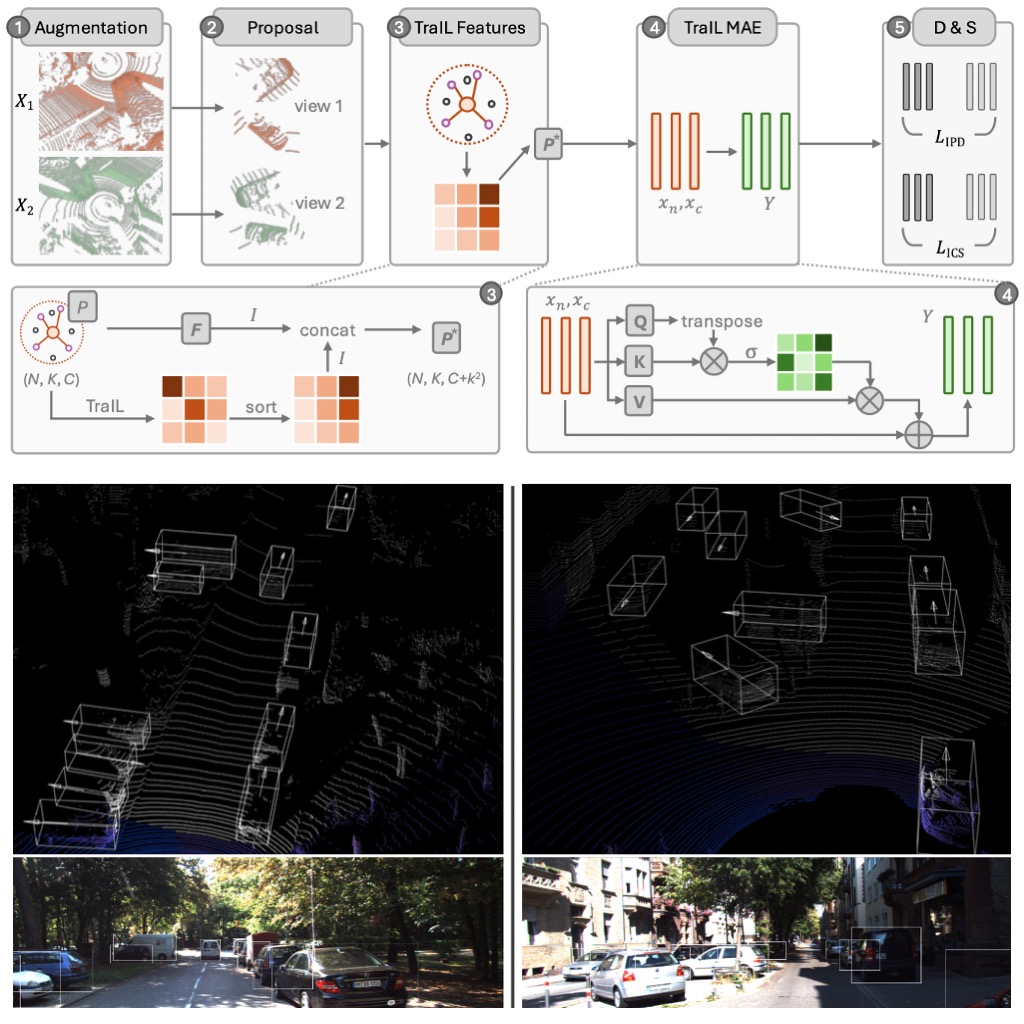
3D point clouds are essential for perceiving outdoor scenes, especially within the realm of autonomous driving. Recent advances in 3D LiDAR Object Detection focus primarily on the spatial positioning and distribution of points to ensure accurate detection. However, despite their robust performance in variable conditions, these methods are hindered by their sole reliance on coordinates and point intensity, resulting in inadequate isometric invariance and suboptimal detection outcomes. To tackle this challenge, our work introduces Transformation-Invariant Local (TraIL) features and the associated TraIL-Det architecture. Our TraIL features exhibit rigid transformation invariance and effectively adapt to variations in point density, with a design focus on capturing the localized geometry of neighboring structures. They utilize the inherent isotropic radiation of LiDAR to enhance local representation, improve computational efficiency, and boost detection performance. To effectively process the geometric relations among points within each proposal, we propose a Multi-head self-Attention Encoder (MAE) with asymmetric geometric features to encode high-dimensional TraIL features into manageable representations. Our method outperforms contemporary self-supervised 3D object detection approaches in terms of mAP on KITTI (67.8, 20% label, moderate) and Waymo (68.9, 20% label, moderate) datasets under various label ratios (20%, 50%, and 100%).
@inproceedings{li24trail,author={Li, Li and Qiao, Tanqiu and Shum, Hubert P. H. and Breckon, Toby P.},title={{TraIL-Det: Transformation-Invariant Local Feature Networks for 3D LiDAR Object Detection with Unsupervised Pre-Training}},booktitle={British Machine Vision Conference (BMVC)},year={2024},month=jul,publisher={BMVA},keywords={autonomous driving, LiDAR, 3D, point cloud, object detection, invariance feature},category={automotive 3Dvision},}
EISEAIT
Inclusive AI-driven Music Chatbots for Older Adults
Farkhandah
Aziz, Effie
Law, Li
Li, and Shuang
Chen
In Engineering Interactive Systems Embedding AI Technologies, May 2024
Today, chatbots are commonly used for music, mainly targeting young people. Yet, there is little research on adapting them for older adults. To address this, we conducted a survey with 20 older adults to understand their music preferences and needs for a chatbot. After developing a prototype based on user requirements identified, we tested it with five older adults, who generally had positive feedback. Moving forward, we aim to explore ways to make the music chatbot more inclusive.
@inproceedings{aziz2024inclusive,title={Inclusive {AI}-driven {Music} {Chatbots} for {Older} {Adults}},booktitle={Engineering Interactive Systems Embedding AI Technologies},author={Aziz, Farkhandah and Law, Effie and Li, Li and Chen, Shuang},publisher={ACM},year={2024},month=may,}
On Deep Learning for Geometric and Semantic Scene Understanding Using On-Vehicle 3D LiDAR
3D LiDAR point cloud data is crucial for scene perception in computer vision, robotics, and autonomous driving. Geometric and semantic scene understanding, involving 3D point clouds, is essential for advancing autonomous driving technologies. However, significant challenges remain, particularly in improving the overall accuracy (e.g., segmentation accuracy, depth estimation accuracy, etc.) and efficiency of these systems. To address the challenge in terms of accuracy related to LiDAR-based tasks, we present DurLAR, the first high-fidelity 128-channel 3D LiDAR dataset featuring panoramic ambient (near infrared) and reflectivity imagery. Leveraging DurLAR, which exceeds the resolution of prior benchmarks, we tackle the task of monocular depth estimation. Utilizing this high-resolution yet sparse ground truth scene depth information, we propose a novel joint supervised/self-supervised loss formulation, significantly enhancing depth estimation accuracy. To improve efficiency in 3D segmentation while ensuring the accuracy, we propose a novel pipeline that employs a smaller architecture, requiring fewer ground-truth annotations while achieving superior segmentation accuracy compared to contemporary approaches. This is facilitated by a novel Sparse Depthwise Separable Convolution (SDSC) module, which significantly reduces the network parameter count while retaining overall task performance. Additionally, we introduce a new Spatio-Temporal Redundant Frame Downsampling (ST-RFD) method that uses sensor motion knowledge to extract a diverse subset of training data frame samples, thereby enhancing computational efficiency. Furthermore, recent advancements in 3D LiDAR segmentation focus on spatial positioning and distribution of points to improve the segmentation accuracy. The dependencies on coordinates and point intensity result in suboptimal performance and poor isometric invariance. To improve the segmentation accuracy, we introduce Range-Aware Pointwise Distance Distribution (RAPiD) features and the associated RAPiD-Seg architecture. These features demonstrate rigid transformation invariance and adapt to point density variations, focusing on the localized geometry of neighboring structures. Utilizing LiDAR isotropic radiation and semantic categorization, they enhance local representation and computational efficiency. We validate the effectiveness of our methods through extensive experiments and qualitative analysis. Our approaches surpass the state-of-the-art (SoTA) research in mIoU (for semantic segmentation) and RMSE (for depth estimation). All contributions have been accepted by peer-reviewed conferences, underscoring the advancements in both accuracy and efficiency in 3D LiDAR applications for autonomous driving.
@phdthesis{li2024deep,title={On {{Deep Learning}} for {{Geometric}} and {{Semantic Scene Understanding Using On-Vehicle 3D LiDAR}}},author={Li, Li},year={2024},month=jul,school={Durham University},type={phdthesis},}
arXiv
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
Jiahao
Sun, Xiang
Xu, Lingdong
Kong, Youquan
Liu, Li
Li, and
8 more authors
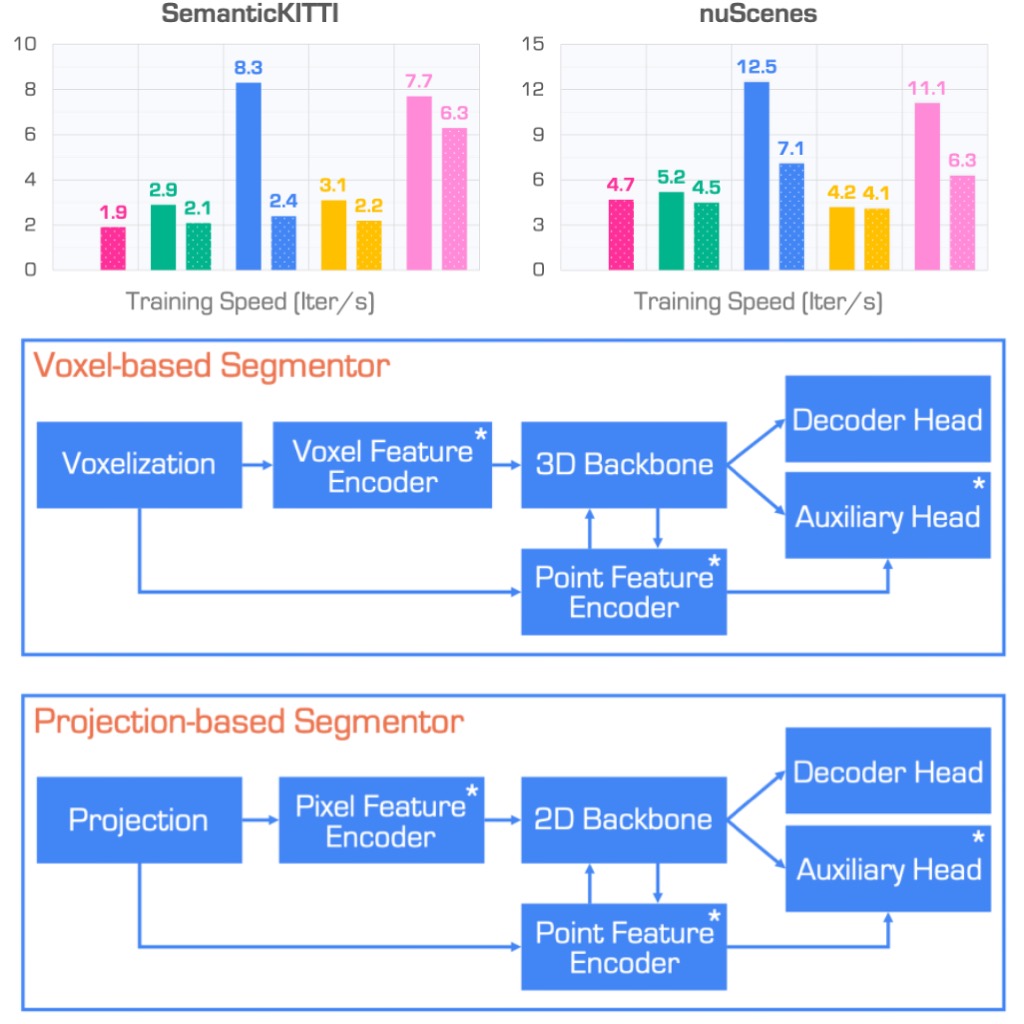
In the rapidly evolving field of autonomous driving, precise segmentation of LiDAR data is crucial for understanding complex 3D environments. Traditional approaches often rely on disparate, standalone codebases, hindering unified advancements and fair benchmarking across models. To address these challenges, we introduce MMDetection3D-lidarseg, a comprehensive toolbox designed for the efficient training and evaluation of state-of-the-art LiDAR segmentation models. We support a wide range of segmentation models and integrate advanced data augmentation techniques to enhance robustness and generalization. Additionally, the toolbox provides support for multiple leading sparse convolution backends, optimizing computational efficiency and performance. By fostering a unified framework, MMDetection3D-lidarseg streamlines development and benchmarking, setting new standards for research and application. Our extensive benchmark experiments on widely-used datasets demonstrate the effectiveness of the toolbox. The codebase and trained models have been publicly available, promoting further research and innovation in the field of LiDAR segmentation for autonomous driving.
@misc{sun2024empirical,title={An {{Empirical Study}} of {{Training State-of-the-Art LiDAR Segmentation Models}}},author={Sun, Jiahao and Xu, Xiang and Kong, Lingdong and Liu, Youquan and Li, Li and Zhu, Chenming and Zhang, Jingwei and Xiao, Zeqi and Chen, Runnan and Wang, Tai and Zhang, Wenwei and Chen, Kai and Qing, Chunmei},year={2024},number={arXiv:2405.14870},primaryclass={cs},publisher={arXiv},doi={10.48550/arXiv.2405.14870},urldate={2024-05-25},}
Whilst the availability of 3D LiDAR point cloud data has significantly grown in recent years, annotation remains expensive and time-consuming, leading to a demand for semi-supervised semantic segmentation methods with application domains such as autonomous driving. Existing work very often employs relatively large segmentation backbone networks to improve segmentation accuracy, at the expense of computational costs. In addition, many use uniform sampling to reduce ground truth data requirements for learning needed, often resulting in sub-optimal performance. To address these issues, we propose a new pipeline that employs a smaller architecture, requiring fewer ground-truth annotations to achieve superior segmentation accuracy compared to contemporary approaches. This is facilitated via a novel Sparse Depthwise Separable Convolution module that significantly reduces the network parameter count while retaining overall task performance. To effectively sub-sample our training data, we propose a new Spatio-Temporal Redundant Frame Downsampling (ST-RFD) method that leverages knowledge of sensor motion within the environment to extract a more diverse subset of training data frame samples. To leverage the use of limited annotated data samples, we further propose a soft pseudo-label method informed by LiDAR reflectivity. Our method outperforms contemporary semi-supervised work in terms of mIoU, using less labeled data, on the SemanticKITTI (59.5@5%) and ScribbleKITTI (58.1@5%) benchmark datasets, based on a 2.3x reduction in model parameters and 641x fewer multiply-add operations whilst also demonstrating significant performance improvement on limited training data (i.e., Less is More).
@inproceedings{li2023less,title={{{Less Is More}}: {{Reducing Task}} and {{Model Complexity}} for {{3D Point Cloud Semantic Segmentation}}},author={Li, Li and Shum, Hubert P. H. and Breckon, Toby P.},keywords={point cloud, semantic segmentation, sparse convolution, depthwise separable convolution, autonomous driving},year={2023},month=jun,publisher={{IEEE}},booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},}
We present DurLAR, a high-fidelity 128-channel 3D LiDAR dataset with panoramic ambient (near infrared) andreflectivity imagery, as well as a sample benchmark usingdepth estimation for autonomous driving applications. Ourdriving platform is equipped with a high resolution 128channel LiDAR, a 2MPix stereo camera, a lux meter anda GNSS/INS system. Ambient and reflectivity images aremade available along with the LiDAR point clouds to facilitate multi-modal use of concurrent ambient and reflectivityscene information. Leveraging DurLAR, with a resolutionexceeding that of prior benchmarks, we consider the task ofmonocular depth estimation and use this increased availability of higher resolution, yet sparse ground truth scenedepth information to propose a novel joint supervised/self-supervised loss formulation. We compare performance overboth our new DurLAR dataset, the established KITTI benchmark and the Cityscapes dataset. Our evaluation shows ourjoint use supervised and self-supervised loss terms, enabledvia the superior ground truth resolution and availabilitywithin DurLAR improves the quantitative and qualitativeperformance of leading contemporary monocular depth es-timation approaches (RMSE= 3.639,SqRel= 0.936).
@inproceedings{li21durlar,author={Li, Li and Ismail, K.N. and Shum, Hubert P. H. and Breckon, Toby P.},title={{{DurLAR}}: A {{High-Fidelity}} {{128-Channel}} {{LiDAR Dataset}} with {{Panoramic Ambient and Reflectivity Imagery}} for {{Multi-Modal}} {{Autonomous Driving Applications}}},booktitle={International Conference on 3D Vision (3DV)},year={2021},month=dec,publisher={IEEE},keywords={autonomous driving, dataset, high resolution LiDAR, flash LiDAR, ground truth depth, dense depth, monocular depth estimation, stereo vision, 3D},category={automotive 3Dvision},}